
Stats 101 covers how, when comparing two different groups or people, it’s not enough to simply state what the average differences are.
We see this in those interminable discussions about who is the GOAT of this or that sport. We can simply compare their average numbers of points, but the NBA now might be scoring more points than the NBA in the 1990s, so while Lebron James may be scoring more points than Michael Jordan, some of that might simply because the NBA is different now (I am fabricating the details out of thin air, much to the horror of my oldest I have no idea nor do I care about the basketball GOAT debate).
We can kind of get around this by, say, subtracting James’ points from the average for the league in 2025 and subtracting Jordan’s from the same in 1995 and compare the raw numbers. This helps, but it still doesn’t adjust for the distribution. If the NBA league in 2025 has a massive spread—meaning scores swing wildly and being 10 points above average is actually quite common—then James’ lead isn’t that statistically significant. However, if the 1995 league was incredibly tight, where almost everyone scored within 2 points of the average, then Jordan being 10 points ahead makes him a statistical outlier of epic proportions.
To solve this, we can take Jordan’s score in terms of how many standard deviations above the mean he is. Standard deviations is a measure of spread; we don’t need to go into mathematical detail suffice it to say that two standard deviations above and below the average covers about 95% of the scores in the NBA (or times in a race, or IQ scores, or most other things).
One thing that’s nice about measuring differences by standard deviations is that we can compare very different things on an apples-to-apples basis. It functions as sort of a universal translator for differences. So, with that, in order to really get a sense of how much more religious Latter-day Saints are in a way that takes the background and distribution of religiosity of the US into account, I decided to compare religiosity with a distribution we all sort of intuitively know about: height. If religiosity was height, how tall would Latter-day Saints be? Technical details are in the appendix.
Conclusion
We’re more religious than average at about the same level that agnostics are less religious than average (about .8 standard deviations above and below the mean, respectively). In height terms, compared to the average man of 5’10, Latter-day Saints are about 6 feet and a half inch if their religiosity was converted to height (while agnostics are about 5’7 and a half). I also ran these numbers for how religious Utah was compared to other states, and I got .23 standard deviations, or about two thirds of an inch of height.
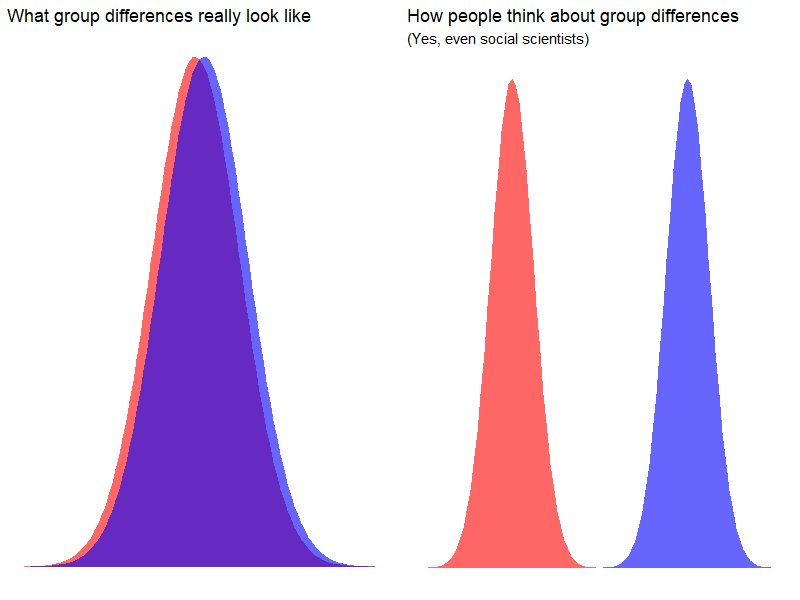
If these don’t sound like large differences to you, and you were expecting Latter-day Saints or Utahns to be NBA stars, religiously speaking, here is a meme I ran across.
Technical Details
I drew from (what else) the Cooperative Election Study. Specifically, I subset all of the 2020 years to get a solid Latter-day Saint sample size. I then calculated the weighted mean and weighted standard deviation of the religious attendance measure (inverted, since the directionality originally has more attendance having a lower score for some reason). I then ran a weighted average by group and then generated Z-scores from those averages.
|
|
Mean Attend |
Z-Score |
| Protestant |
3.664933
|
0.527574
|
|
Catholic
|
3.182531
|
0.246786
|
|
Latter-day Saint
|
4.128595
|
0.797454
|
|
Eastern Orthodox
|
3.525713
|
0.44654
|
|
Jewish
|
2.717053
|
-0.02415
|
|
Muslim
|
3.877352
|
0.651215
|
|
Buddhist
|
2.279949
|
-0.27857
|
|
Hindu
|
3.084211
|
0.189558
|
|
Atheist
|
1.180842
|
-0.91832
|
|
Agnostic
|
1.377244
|
-0.804
|
|
Nothing in particular
|
1.755717
|
-0.58371
|
|
Something Else
|
2.847257
|
0.051636
|
I then found an estimate for the mean and SD of height of men in the US (I found a couple different estimates that varied slightly, I settled on an average of 5’10 with a SD of 3 inches), and then used that to generate a graph of Z-scores by inch-by-inch (male) height.
| Height | Z-Score |
|
5’0″
|
-3.33333
|
|
5’1″
|
-3
|
|
5’2″
|
-2.66667
|
|
5’3″
|
-2.33333
|
|
5’4″
|
-2
|
|
5’5″
|
-1.66667
|
|
5’6″
|
-1.33333
|
|
5’7″
|
-1
|
|
5’8″
|
-0.66667
|
|
5’9″
|
-0.33333
|
|
5’10”
|
0
|
|
5’11”
|
0.333333
|
|
6’0″
|
0.666667
|
|
6’1″
|
1
|
|
6’2″
|
1.333333
|
|
6’3″
|
1.666667
|
|
6’4″
|
2
|
|
6’5″
|
2.333333
|
|
6’6″
|
2.666667
|
|
6’7″
|
3
|
|
6’8″
|
3.333333
|
|
6’9″
|
3.666667
|
|
6’10”
|
4
|
|
6’11”
|
4.333333
|
|
7’0″
|
4.666667
|
Code
library(haven)
library(pollster)
df <- read_dta(“~/Desktop/dataverse_files/cumulative_2006-2024.dta”)
df<-subset(df, year>2019)
#Weight_cumulative: https://cces.gov.harvard.edu/frequently-asked-questions
attributes(df$religion)
attributes(df$relig_church)
table(df$relig_church)
attributes(df$state)
table(df$relig_church)
df$relig_church[df$relig_church %in% c(7, 8)] <- NA
df$relattend <- 7 – df$relig_church
table(df$relattend)
weighted.mean(df$relattend, df$weight_cumulative, na.rm = TRUE)
wtd.mean(df$relattend, df$weight_cumulative)
library(Hmisc)
sqrt(wtd.var(df$relattend, weights = df$weight_cumulative, na.rm = TRUE))
library(matrixStats)
weightedSd(
x = df$relattend,
w = df$weight_cumulative,
na.rm = TRUE
)
#2.758545 is the mean for relattend
#1.718029 is the SD
library(dplyr)
religdf<-df %>%
group_by(religion) %>%
summarise(
mean_relattend = weighted.mean(relattend, weight_cumulative, na.rm = TRUE)
)
test<-subset(df, religion==3)
wtd.mean(test$relattend, test$weight_cumulative)
attributes(df$religion)
statedf<-df %>%
group_by(state) %>%
summarise(
mean_relattend = weighted.mean(relattend, weight_cumulative, na.rm = TRUE)
)
religdf$ZScore<-(religdf$mean_relattend-2.758545)/1.718029
statedf$ZScore<-(statedf$mean_relattend-2.758545)/1.718029
#Sources for standard deviations for height
#https://distributionofthings.com
#For the US: https://www.maxwachtel.com/blog-1/2020/6/22/statistics-explained-mean-and-standard-deviation
#5’10, 3 inches slightly different numbers, nice round one.
mean_height <- 70 # 5’10” in inches
sd_height <- 3 # standard deviation in inches
heights_in <- seq(from = 60, to = 84, by = 1)
height_z_df <- data.frame(
height_inches = heights_in,
height_feet_inches = paste0(
heights_in %/% 12, “‘”,
heights_in %% 12, ‘”‘
),
z_score = (heights_in – mean_height) / sd_height
)
Comments
8 responses to “If Religiosity Was Height, How Tall Would Latter-day Saints Be?”
So, at 6’4″, my height sets me apart more than my religiosity.
Of course, and I’m sure you are expecting this to be noted, religiosity is pretty tricky (impossible?) to operationalize and to measure. Attendance is a poor measure, but at least it’s something people track. Back when we met Sundays and mid-week (yeah, I’m that old), maybe we were twice as religious? Now that we meet for 2 hours instead of 3, does that make us 33% less religious than a decade ago? Obviously, the duration or intensity of the meetings isn’t factored into this – and intensity would be so variable as to render it useless. But I take your larger point that we’re not as different as we want to think we are. Thanks!
Your height sets you apart more *if you are as religious as the average Latter-day Saint.*
And yes, religiosity is tricky, but attendance is a nice concrete figure. When people answer how important religion is in their life, for example, it’s hard to know what they’re anchoring it to, or whether they’re talking about importance for them personally or social importance (e.g. religion is extremely important in the lives of Afghan atheists). So yes, attendance has its issues, but every religion measurement does.
I suppose the reason for the perception about group differences illustrated with the drawing above is that a lot of attention is drawn by extremes. So polarizing!
Using the height distribution above (70 inches as the mean and 3 inches as the SD), I considered the US Navy pilot training height requurement. Candidates must be between 62 and 75 inches tall. For a population with a 70-inch mean height 99.944% pass the height qualification. For a population with a mean 2 inches taller and another one with a mean 2 inches shorter (and the same 3-inch SD) the portions with qualifying height are 99.08% and 99.77%. No difference really when considering who passes this qualification, which is only one of many things it takes to become a Navy pilot.
But if you look at who doesn’t qualify for training because they are too tall or too short, the differences are huge. From the 70-inch mean population 0.056% don’t qualify, from the 72-inch mean population 0.92% don’t qualify, and for the 68-inch mean population 0.23% don’t qualify. Those are rejection ratios of 16:1 and 4:1. Small differences in mean make large differences on the tails.
Correction: The US Navy pilot height limits are 62 and 77 inches, not 62 and 75. The numbers above are for the 77-inch limit (2.333 SD above a 70-inch mean).
Yep. We are good at meetings.
I like it…I’m always looking for good ways to help people understand group differences, and height has a distribution we’re all familiar with.
Another way: if you meet a random person, there’s a 50% chance they’ll be more religious than average and a 50% chance they’ll be less religious than average*. If you meet a random Latter-day Saint (more precisely, a random person who identifies as a Latter-day Saint in the CES), these numbers suggest there’s about a 79% chance they’ll be more religious than average, and about a 21% chance they’ll be less religious than average. That’s a big difference, but it would still be dangerous to make assumptions about the religiosity of a particular person. (Of course if you meet a random Latter-day Saint *at church*, that changes things again.)
*Assuming religiosity is normally distributed. If it’s close, the numbers will be close. If it’s not, all bets are off, including the 50/50 chance of a random person being above or below average.
@John Mansfield: Interesting point. Not to throw a grenade in here and it doesn’t deal with averages, but it does remind me of the point Larry Summers made (that got him fired from being President of Harvard) dealing with the effect of different standard deviations (if I recall correctly, don’t remember enough of the details to have an opinion about it) on outliers.
@RLD: Your way of looking at it is super helpful. The probability of meeting somebody more religious perspective makes us see, more religious than my way; for some reason my intuition is that 6 foot people are more common than they are.
For the sake of posterity who may come upon these comments 21 years from now, I wish to correct an error in my example numbers in my comment above. I forgot the 2 factor in the normal distribution exp( -(X-mean)^2/(2*SD^2) ), so the rejection numbers given above are far too low, and the rejection ratios are too high.
The corrected numbers should be:
For a population with a 70-inch mean height, 98.64% qualify and 1.36% are rejected.
For a population with a 72-inch mean height, 95.18% qualify and 4.82% are rejected.
For a population with a 70-inch mean height, 97.59% qualify and 2.41% are rejected.
The rejection ratios are 3.5:1 and 1.8:1.
(Earlier this week I was looking at comments left at this web site following the calling of Elders Uchtdorf and Bednar to the Quorum of the Twelve, 21 years ago at the dawn of “blogging.”)