
There have been several big AI advancements since I last wrote on the subject.
- Gemini 3, the frontier model from Google, was just released. The coding and writing is noticeably, but incrementally better (since they’re releasing models quicker there aren’t any huge jumps anymore like there was from GPT 3.0 to 3.5), but where it really shines is creating interactive apps/games on the fly (for computer, doesn’t work so great for mobile devices as far as I can tell). I generated:
- A first-person, 3D simulation of the tabernacle. I just asked it to create a biblically accurate representation. I didn’t “hard code” any details.
- I did another one for the Temple of Solomon
- I created a flight simulator for flying over the Book of Mormon lands. (This one could have used some additional iterations, and I don’t know my Book of Mormon geography, so I don’t know how accurate it is).
- A Noah’s Ark simulation based on some calculations written by a marine engineer in my ward. (I just uploaded the PDF).
- A family tree simulator that shows your number of descendants given a certain set of parameters.
I also tried to make a “first person spearer” game with Teancum, but that one’s not ready for distribution.
Finally, not LDS-related, but for our homeschooling purposes I made rocket simulator that shows the relative sizes of different layers of the atmosphere. Again, each of these took 1-3 non-technical prompts (except for the rocket ship one, that took 10 or so).
And that’s the main use case here I think. Pedagogy. You can come up with an app or game for learning virtually anything now. We’re not to the point where we can vibe-code Doom yet, but it’s coming. One Google executive thinks we’ll be able to vibe code video games this time next year.
2) A lot of us have excitedly ordered some ancient document in special collections, waited for them to bring the box out to us, and waited with baited breath as we opened the very journal that so-and-so wrote in….only to have no idea what they were saying because we can’t read old handwriting. And then we realized that they have whole classes on the subject before you have the right to engage in the esoteric arts of archival work with 19th century documents. Well, there’s some evidence that Google has solved paleography, so you can upload a photo of whatever arcane document you’re looking at and it will give you a transcription as good or better than a trained human. (So I assume we’ve also solved indexing as well. Thank you for your service, but it’s not like the indexing folks had any idea the technology would be here at this point).
3) #2 is possible thanks to Google’s newest image generator, Nano Banana Pro, which appears to have solved fine-grained writing details and fine-grained control over images.
For example, I asked it to create a chart of all Presidents of the Church in anime style, and this is what it gave me in one shot. Besides pulling youthful photos of some of them for some reason, it’s pretty good.

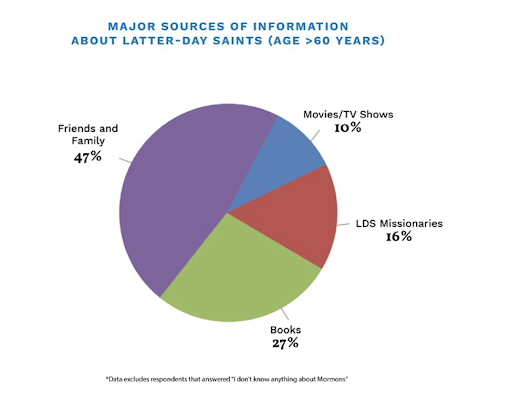
I also uploaded a boring pie chart we made in one of our BH Roberts reports, and asked it to “take this image and put in some really cool-looking subject-specific visualizations and labels. I want to keep the proportionality and numbers and such.”

Finally, I turned the Ammon painting into a photo. It only photo-ized the first layer, but still.

And yes, I know that Elder Gong has warned about untoward uses of AI. I disagree with him about the inappropriateness of depicting deity using AI, but out of respect for his counsel and to be a good member I’ll decline to do any AI artwork involving deity. It’s not any kind of a moral disagreement and I’m not dying on that AI hill, but by the same token if this has gone by the wayside in ten years without any follow-up I’m going to assume that it’s gone the way of Adam-God or the Deseret Alphabet and I’m not going to feel bound by it.
3) I’ll have to admit I was a little underwhelmed by OpenAI’s latest entry into the AI movie race with Sora 2, but Christopher Blythe has really taken to it and made some fun LDS-related content.
4) Music: The latest version of Suno, the frontier music model, is quite good. I haven’t ponied up the 8 bucks a month for it, but it seems capable of creating ear worm songs and catchy tunes. Headlines blared the fact that an AI generated song was #1 on the country music charts, but the fine print here was important, since evidently it was just #1 in a very specific chart (digital single downloads). So it’s not to Stairway to Heaven yet, but it’s as catchy as most other stuff out there now.
Comments
8 responses to “Latest AI Updates and the Church”
“It’s pretty good”?
Nine out of eighteen are unrecognizeable, and youthening them isn’t the problem. But I forgive it all for the gift of spiky-haired Joseph Smith.
AI has not solved paleography. It’s gotten a lot better at handwriting recognition, though, and that’s real progress. When I need an electronic text to work with, it’s already faster to let a VLM handle the first pass and then make corrections, and a character error rate of 8-10% is a pretty reasonable starting point. I’m guessing that Google has included more historical writing samples in its training data, which is a real plus.
I mostly work with smaller VLMs, but I don’t think a lot of reasoning about language is going on – they’re still just taking guesses based on their training data when they come to character sequences they don’t recognize. (And this is an area where I don’t think it takes a frontier model and a data center – the amount of world knowledge and vision capability you need for OCR just isn’t that much, and I suspect that smaller, focused models could be just as good, if anyone cared to train them on 17th-century Norwegian church books, or whatever.)
18-19th century English handwriting samples (which the linked blog post looks at) are only going to get you so far with other languages and time periods, and finding training data for early centuries isn’t straightforward. Hopefully training data keeps getting added, because I would love it if AI could handle more of the laborious text scanning, or do it more accurately than it currently does.
@Jonathan: That’s a good point, I’m being American-centric here. IIRC “Humanity’s Last Exam,” a benchmark test designed to be very difficult for AI to solve, has some ancient language analysis involved.
“(So I assume we’ve also solved indexing as well. Thank you for your service, but it’s not like the indexing folks had any idea the technology would be here at this point).”
My understanding is that the indexing done earlier was used to train the AI. If you go to Family Search now, it no longer has opportunities for direct indexing. Instead, you’re being asked to verify/correct what the AI has already done, which is then fed back to the AI so it will get even better. Just saying that the human indexing work done before wasn’t pointless.
The AI laid one heck of a disapproving scowl on Joseph Fielding Smith.
I’m also not generally a fan of the Presidents of the Church chart, but I agree Joseph Smith with anime hair makes it all worthwhile.
I’m kind of impressed with the creativity of the pie chart, but as a means of communicating information it’s really bad.
Curtis Pew makes an excellent point. AI indexing is now possible because of the countless hours humans spent indexing. Those hours were not wasted: the fact that their output could be used to train an AI that can now do indexing much more quickly makes them even more valuable.
This applies to all generative AI, and should be remembered when we think about who should receive the rewards of AI’s “labor.”
@Curtis Pew & RLD: Good point re the indexing, I wouldn’t be surprised if the Church had on of the largest corpuses (corpi?) of human-checked 19th century writing.
Plural: corpora